Note: Following this is not for the faint of heart. If you aren’t comfortable with partitioning, then don’t follow the steps here. I’ve read many posts on how to handle ZFS/Raid-Z on differently sized disks. The goal is to gain the most disk space availability while still retaining the redundancy of surviving a single disk failure. The posts I’ve read either would achieve the theoretical capacity, or be capable of expansion, but not both. I devised a way to get both at the same time, and it’s relatively simple.
The problem is the following: A Raid-Z configuration uses n partitions, giving the user the capacity of n-1 of those partitions, with the nth being the redundant to survive a failure. If the n partitions are not the same size, with the smallest being x, only the first x bytes of each partition is used. One cannot remove a Raid-Z from an active pool without a backup/restore. One cannot add a disk to a Raid-Z without a backup/restore (maybe in the future). The only expansion that can be done is to replace the partitions with larger ones, and once the smallest partition is increased, the available space increases.
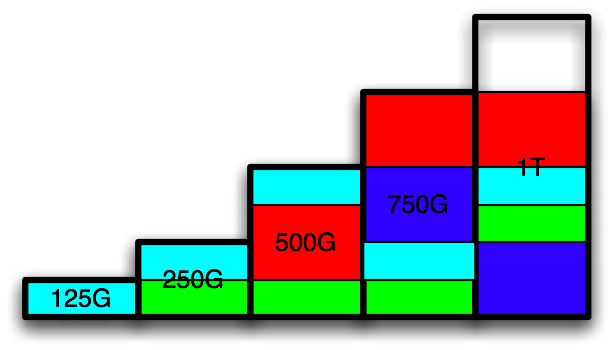
For the purposes of demonstrating this technique, I will use an example with 4 disks:
- 125G
- 250G
- 500G
- 750G
The biggest theoretical capacity of the array, while retaining single disk failure resiliency, is simply the total size of the array minus the largest disk. This means that the capacity of the above example is 875G. So, how does one achieve this capacity? I proposed the following structure using 3 raids:
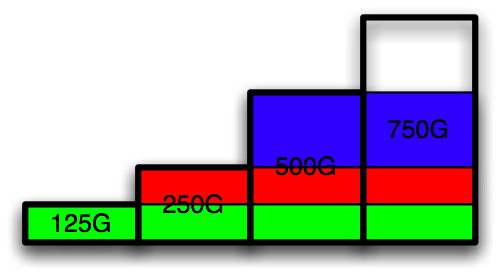
If you add the capacity in the above, you can see it is 3*125G + 2*125G + 250G = 875G, which is the theoretical capacity.
Suppose I wish to replace the smallest disk, 125G, with a new disk, say 1T. Using the same layout, I should see something like this:
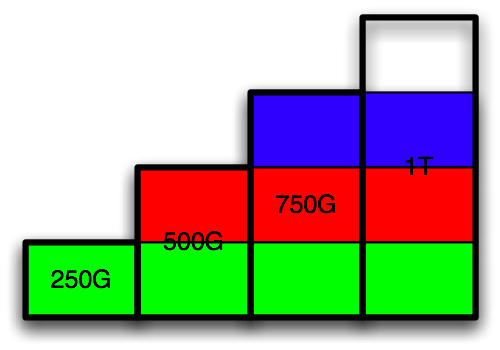
The question is, can I migrate from the first configuration to the last without a backup/restore process? The answer is YES, and data is moved/copied at most once.
For the purposes of demonstration, I’m going to show the expansion with 5 drives connected, but the expansion can be done by immediately replacing the smallest drive with the largest and relying on the redundancy to keep things intact in the process.
First, connect the 1T drive and partition it as 250G, 250G, 250G, leaving the rest free. Replace the first 125G partition on 750G disk with the first 250G partition on the 1T disk:
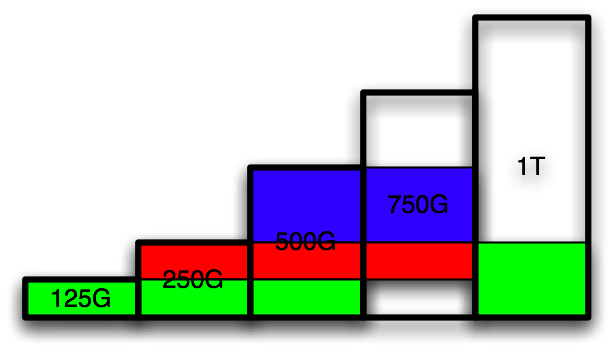
Continue the replacement:
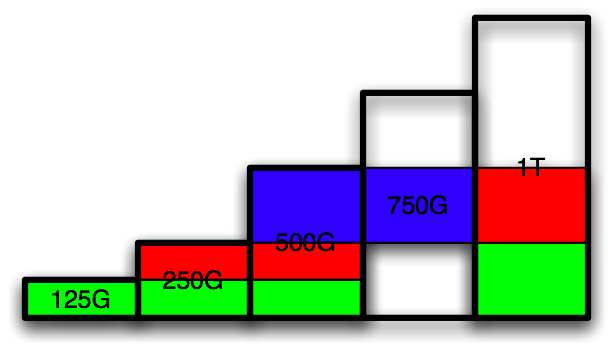
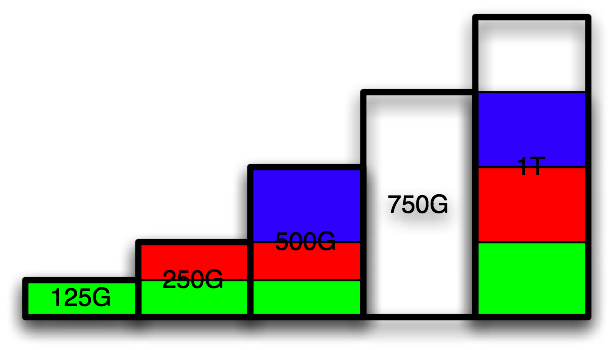
Repeat the same process with the 3 partitions on the 500G disk:
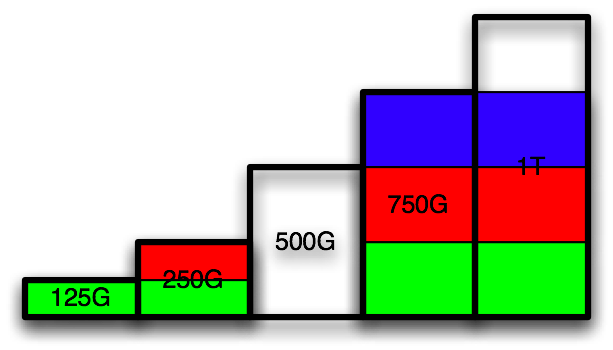
Repeat with the 2 partitions on the 250G disk:
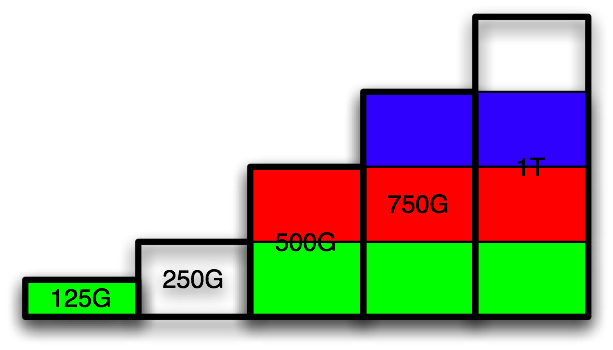
Repeat for the final time with partition on the 125G disk:
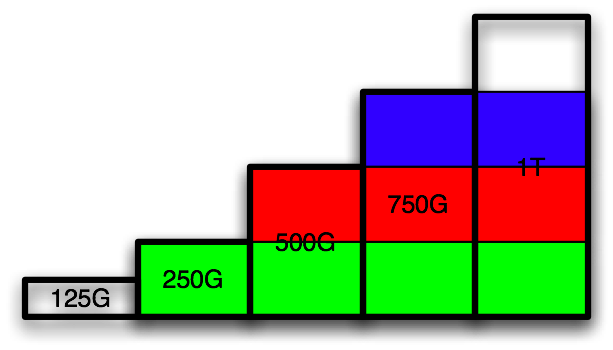
Note: There is one limitation with this structure. Ordering the disks in increasing size, disk(n) must be at least as big as 2*(disk(n-1))-disk(n-2). This essentially means that if a disk is xG bigger than it’s previous disk, then the next disk must be at least xG bigger than this disk. Since disk sizes tend to grow exponentially, this assumption shouldn’t be much of a problem since the requirement is at least linear growth.
The disk sizes in this example meet the requirement I listed above. Given the requirements of this expansion, the disk added in this example must be at least 1000G, since disk 4 is 250G bigger than disk 3, disk 5 must be at least 250G bigger than disk 4, or 1000G.
This technique also allows adding another disk, under the same conditions. Consider adding a 1T disk and creating another Raid-Z:
Anyway, I thought of this while considering using ZFS/Raid-Z in a FreeNAS setup. I haven’t tested any of this; it’s theoretical only. What do you think?
Legacy Comments:
vlhorton - Apr 9, 2010
I think it is genius! have you looked at the sun open storage stuff?
Graham Booker - Apr 9, 2010
vlhorton, No, I haven’t but I did in looking at your suggestion. Considering that I’m considering a storage solution for myself, Sun’s open storage is too expensive for what you get. In my case, I don’t need extremely high performance, but rather cheap storage.
Steffen - Mar 30, 2011
Thanks. Looks good although my collection of discs is 3x500 and one 1.5 TB I’ll probably try it out.
Graham Booker - Mar 30, 2011
With 3x0.5T + 1x1.5T, you can really only do a single raidz, with 0.5T on each disk. There’s no advantage to the technique in this post. If you replace a disk with a larger one, then you start to see an advantage.
Steffen - Mar 29, 2011
Hi, Nixe idea! Am I tight that in the first example you basically end up with 3 raidz’s ? do you combine these or are these different partitions later? Thanks
Graham Booker - Mar 29, 2011
Steffen, Yes, it is three raidzs, on different partitions. It remains three raidzs that are part of the same pool.
Tobias - May 22, 2011
I notice that it’s been a while since you wrote this post. Have you tested it yet? Perhaps in a virtual machine? Your idea seems nothing but brilliant, and I love this kind of thought experiments. The reason I found this post is that I am thinking of just a setup like this for myself; a FreeNAS node using the (differently sized) disks that I already have. Now, I’m sure that it can be looked up somewhere, but I think some info is hard to interpret, so I’ll ask: Can an existing RAIDZ partition be extended to a larger number of disks? E.g., in the first example above, could the blue partition be a three-way RAIDZ (given that another HDD was added, obviously), without destroying the existing RAIDZ? It would be rather neat to be able to add, instead of 1TB, 2x1TB which both hold one green, one red and one blue RAIDZ “slice” each.
Graham Booker - May 23, 2011
Tobias, I have tested this insdie a VM, but that is the extent of what I’ve tried. To answer your question, you cannot change the width of an existing RaidZ (called a vdev). You can only increase the size of each individual slice and add additional vdevs. You cannot decrease the size of a vdev, change it’s width, or remove a vdev from the pool.
zpool hasn’t expanded - The UNIX and Linux Forums - Aug 29, 2012
[…] See ZFS on different sized disks. […]
Amedee Van Gasse - Dec 16, 2012
This is a clever config, but doesn’t ZFS prefer direct access to the disk over partitions? That’s how I understand the documentation. I am considering a similar partition scheme, but with ext4 or btrfs.
Graham Booker - Dec 17, 2012
ZFS is perfectly happy to work in partitions. I think that whole disk has a slight optimization and ZFS can operate without a partition unlike many other FSs.
tom - Feb 5, 2014
Graham, Interesting read, looking at doing this for the first time for myself as i’m running separate disk with no redundancy! (Although I have a manual backup). I know this is a old post now but it seems still relevant, in relation to the guy who has 3 x 500gb and 1 x 1.5tb, why cant he use 500gb partitions and effectively use the 500gb drives as 1 drive against the 1.5tb? If the 1.5tb fails then the data is on the 3x500gb and if one of the 500gb fails then the data is on the 1.5tb? thx, tom,
Graham Booker - Feb 6, 2014
Tom, you are correct in banding together 3x500G into a 1.5T and then mirroring that with another 1.5T to achieve redundancy, but these two actions cannot be done in ZFS simultaneously. Doing a raidz across the 3x500G and 1.5T does achieve 1.5T of data that’s protected against a single drive failure, and leaves 1T on the large disk unused which could be re-purposed for other means.
tom - Feb 7, 2014
Ah ok, thanks for your input and brilliant article. :)
Kirk - Feb 1, 2015
How does this translate to RAIDZ3?
Graham Booker - Feb 2, 2015
Kirk: The techniques and conclusions listed here would expand to raidz3 and work mostly the same as they do with raidz1, just wider. The primary difference is that the smallest vdev would contain 4 disks and the total capacity would the sum of the disks minus the 3 largest. Although I should stress that if you are considering raidz3 it sounds like you are investing sufficient money that you’d be far better off buying equal sized disks and creating a single vdev.
- Feb 6, 2017
Doesn’t a raidz require 3 drives/partitions minimum? Your “blue” raid would be a mirror I guess?
Graham Booker - Feb 6, 2017
If one were to look at how the algorithm for raidz would work for a 2 disk vdev, it would behave identically to a mirror. So whether a 2 disk raidz is allowed or the user must specify a mirror, the end result is the same. So, yes, the “blue” vdev would be a mirror.